Optimizing AI Inference with Edge Computing


In this article, we look at how edge computing can optimize AI workloads, focusing on inference sub-systems such as tokenization and RAG.
We also share results from our internal research, showing how edge computing can reduce latency and cost while improving the end-user experience.
What's wrong with the centralized approach?
Modern AI is highly centralized. Most interactions - from GPT-powered chatbots to video platforms - involve sending requests to a handful of GPU clusters in faraway data centers.
This architectural model is driven by several practical constraints. Operationally, these monoliths are easier to monitor, patch, and iterate on. Moreover, they provide economies of scale by lowering infrastructure costs as output grows.
Training was long considered the major bottleneck, which partly motivated these setups. Today, however, the bottleneck is shifting to inference.
There are two main downsides when running inference on centralized architectures:
- Network Latency: users far from the data center experience hundreds of extra milliseconds of delay.
- Strain: a small number of GPU servers must handle millions of concurrent requests.
To alleviate these issues, you could distribute the computation across multiple servers that are physically closer to your users.
This is where the edge has some advantages to offer.
What can you offload to the edge?
The “edge” refers to the hundreds of points of presence (PoPs) that CDNs and ISPs have operated worldwide for decades. Originally designed to serve and cache web assets, these edge nodes sit physically closer to end users and have become increasingly programmable through technologies like WebAssembly, containers, or lightweight functions.
This makes the edge a natural platform for the next generation of AI systems.
For example, at Edgee we built a globally distributed platform that allows you to build, use, and distribute WebAssembly components at the edge.
Looking at traditional AI inference pipelines, the big question is: what could be offloaded to the edge?
From the outside, AI inference looks like a single process: matrix multiplication on GPU chips. But zooming in, it's made of several smaller processes, some of which are simple CPU-bound algorithms that don't rely as heavily on GPU infrastructure.
Let's take a look at two examples: tokenization and RAG.
Example 1: Tokenization
Tokenization is a critical pre-processing step that breaks down a sequence of characters (your prompt) into smaller, meaningful units called tokens.
Tokens are the building blocks that AI models operate on. Instead of working with raw text directly, they operate on numerical representations of these tokens.
Tokenization algorithms are relatively simple and CPU-bound. One of the most commonly used ones today is Byte Pair Encoding (BPE), originally described back in 1994. Despite being over 30 years old, researchers continue to optimize it.
In the context of LLMs, tokenization usually runs on the inference server and presents a good tradeoff compared to encoding the input prompt at the character level.
At Edgee, we explored how tokenization could run at the edge. Instead of sending a raw payload to a remote server, the edge network tokenizes the input prompt and sends only the tokenized results to the model. This approach can reduce latency, especially on large inputs.
With tokenization at the edge, we observe averageround-trip time improvements of ~20ms.

Statistics summary:
- Average latency improvement ~20ms
- Average payload size gains ~35%
- Reference data: The Stack dataset
Of course, it's worth noting that tokenization algorithms are heavily input sensitive, so compression results can vary depending on the input language. While the impact on individual requests may not be a game-changer for end users, offloading CPU computation to a distributed network of edge nodes also removes unnecessary load from the main centralized servers, allowing further optimizations. Moreover, having tokens available at the edge enables additional checks, such as ensuring context windows are not exceeded early in the process.
We look forward to running more experiments in the near future, looking at specific use cases such as much larger prompts and entire code repositories, where the impact of tokenization might lead to larger savings.
When it comes to tokenizing large amounts of code, you can usually adopt alternative techniques to build prompts and optimize for accuracy. For example, with RAG.
Example 2: RAG (Retrieval-Augmented Generation)
LLMs have access to a massive amount of data. This data is typically ingested into the model during the training phase, making it hard to access unseen or up-to-date information at inference time.
Including the information in the prompt can be a solution, but when the information gets too large, several problems arise. For example, exceeding the context window or introducing so much information that accuracy declines.
RAG is designed to solve this problem by integrating (trusted) data at inference time. The idea is to include only the relevant parts that are semantically related to the prompt.
This process involves three steps:
- Indexing - extract metadata and make it searchable using a vector database.
- Prompt Building - augment the given prompt with relevant information from the vector database.
- Inference - send the augmented prompt to your LLM of choice.
Let's take a closer look at these concepts.
A quick dive into Indexing, Embeddings and Vector Databases
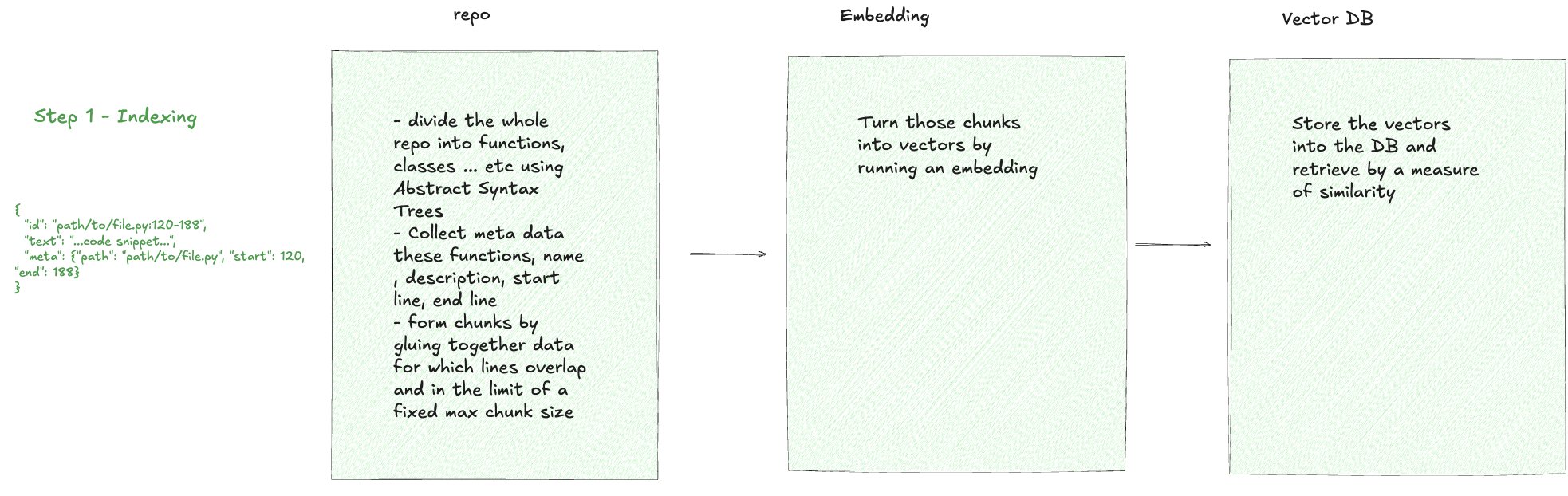
At first, you build an index of the documents at hand. This is done through chunking document metadata and storing these chunks into a vector database.
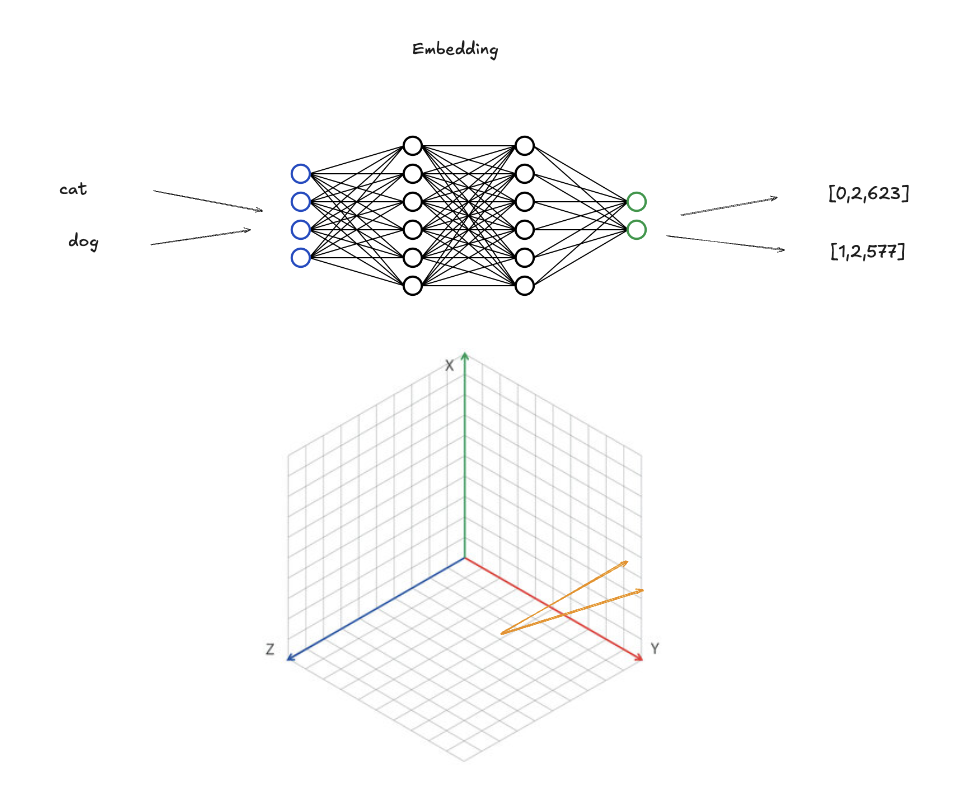
In simple terms, a vector database is a data structure where every entry is stored as a vector, obtained by running an embedding model.
An embedding model is a neural network that encodes semantic meaning, mapping similar words to vectors that are close in the output space.
You can query the vector database using a similarity measure (cosine for example), by retrieving all the vectors similar to the query vector.
For example, let's consider the case of a code repository.
The index stores chunks of function and class names, scope, and line numbers in the vector database.
Prompt Building
When users enter a prompt, you send it to your RAG system first. Here, you query the vector database and retrieve all the relevant context. For example, you might retrieve the top five most relevant files or functions in your codebase for the LLM to modify.
Then, you can use this metadata to extract the context locally - for example, the actual code corresponding to the most relevant files and functions.
Finally, you append this code to the raw prompt, then send it to the LLM.

Where can you run RAG?
In most systems, all these steps happen on a centralized server, even if only the inference requires a GPU.
That's why we believe that RAG is a natural candidate for the edge.
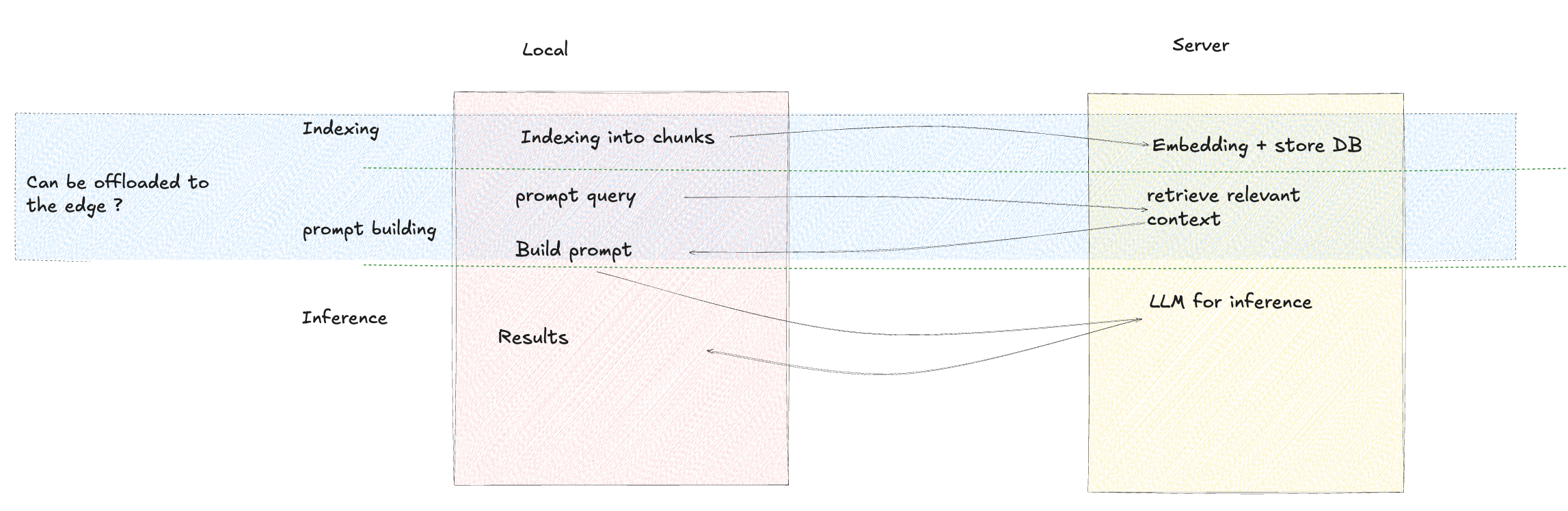
We tested this approach and observed significant latency improvements. By offloading the embedding and vector database to the edge, RAG can run as close as possible to end users, drastically reducing round-trip latency.
Assuming a centralized server in the US, the latency improvement is already significant for users in North America (15% faster on average):

And it becomes even more impactful for users in Europe/France (145% faster on average, shaving off over 340ms):

Overall, we observe major latency improvements when running RAG at the edge. This improves the end-user experience while offloading non-GPU workloads from centralized servers.
Conclusions and next steps
We will continue exploring edge offloading and optimizations, focusing on additional use cases and techniques. For example, the RAG use case could be extended with semantic caching at the edge, further enhancing the end-user experience.
